Introduction
Large Language Models (LLMs) have become an integral part of our daily lives, powering everything from chatbots to code generation tools. However, these models are typically trained for general purposes, and in many cases, we may need them to specialize in a particular domain or use case. This is where LLM fine-tuning comes into play, allowing us to adapt these powerful models to our specific needs. The challenge, however, is that fine-tuning such massive models requires substantial computational resources—far beyond what is available for free. To address this, researchers have developed techniques like LoRA (Low-Rank Adaptation) and its optimized variant, QLoRA (Quantized LoRA), which significantly reduce the resource requirements for fine-tuning while maintaining model performance. In this blog, we’ll explore how QLoRA enables efficient fine-tuning of LLMs on limited hardware.
LoRA and QLoRA
LoRA :
It works by adding a smaller number of new weights to the model, which are then trained, rather than retraining the entire model or adding new layers for new tasks. It keeps the original model unchanged and adds small, changeable parts to each layer of the model. This significantly reduces the trainable parameters of the model and reduces the GPU memory requirement for the training process.
Low Rank Matrices: Low Rank Matrices are very important with respect to LoRA working. A matrix is of lower rank if its rank is less than the maximum possible given its size. For example, in a 3x3 matrix, if the rank is less than 3, it's a lower rank matrix. Lower rank matrix helps in compressing the data while preserving as much information as possible.Large models have a lot of parameters. For example, GPT-3 has 175 billion parameters. These parameters are just numbers stored in matrices. Storing them requires a lot of storage. Full fine-tuning means all the parameters will be trained, and this will require an extraordinary amount of compute resources that can easily cost in the millions of dollars for a model size like GPT. Unlike traditional fine-tuning that requires adjusting the entire model, LoRA focuses on modifying a smaller subset of parameters (lower-rank matrices), thereby reducing computational and memory overhead.
Reducing the matrix to low rank:In transformer models, the weight matrix \( W \) in a linear layer transforms input features \( x \): \( y = Wx \)
where:
- \( W \in \mathbb{R}^{d \times k} \) (Full-rank matrix)
- \( x \in \mathbb{R}^{k} \) (Input features)
During fine-tuning, updating \( W \) requires \( d \times k \) trainable parameters, which is costly.
LoRA OptimizationInstead of updating \( W \) directly, LoRA introduces two small trainable matrices \( A \) and \( B \) of rank \( r \): \(\Delta W = BA \)
where:
- \( A \in \mathbb{R}^{d \times r} \) (Tall and thin)
- \( B \in \mathbb{R}^{r \times k} \) (Short and wide)
- \( r \ll \min(d,k) \) (Much smaller rank)
Since \( \Delta W \) is the product of two low-rank matrices, it captures model updates with far fewer parameters.
Parameter Reduction with LoRAInstead of \( d \times k \) parameters in full fine-tuning, LoRA requires: \(r(d + k)\)
For example, if:
- \( d = 4096, k = 4096 \)
- Full fine-tuning requires: 16.7M parameters
- With \( r = 64 \), LoRA only trains: 524K parameters
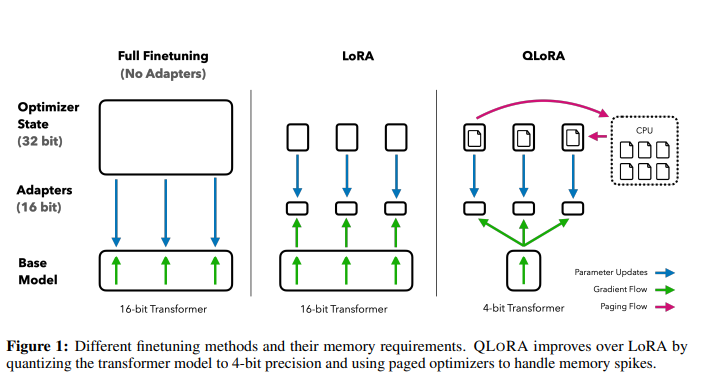
QLoRA:
QLoRA represents a more memory-efficient iteration of LoRA. QLoRA takes LoRA a step further by also quantizing the weights of the LoRA adapters (smaller matrices) to lower precision (e.g., 4-bit instead of 8-bit).
Core Idea:- Storing model weights in 4-bit precision
- Converting them to 16-bit only when needed for computations
- Using special techniques to maintain accuracy despite the compression
- NormalFloat(NF4) Quantization: 4-bit NormalFloat Quantization is a method designed to efficiently quantize the weights of neural networks into a 4-bit format. NormalFloat data type is designed to optimally quantize data, particularly for use in neural networks and based on a method called “Quantile Quantization” which ensures that each bin (or category) in the quantization process has an equal number of values from the input data.
- Double Quantization: Double quantization is the process of quantizing the quantization constant to reduce the memory down further to save these constant.
- Paged Quantization: When training large models with billions of parameters GPU’s running out of memory is common problem. Paged optimizers are used to address these memory spikes that occur during model training. NVIDIA unified memory facilitates automatic page-to-page transfers between the CPU and GPU, similar to regular memory paging between CPU RAM and the disk. When the GPU runs out of memory, these optimizer states are moved to the CPU RAM and are transferred back into GPU memory when needed.
Implementation
Much of the below code is just important steps and configurations for the training. For entire code see here
- Loading dataset:
dataset = load_dataset("Amod/mental_health_counseling_conversations")
train_test_split = dataset["train"].train_test_split(test_size=0.3, seed=42)
test_validation_split = train_test_split["test"].train_test_split(test_size=1/3, seed=42)
dataset_train = train_test_split["train"]
dataset_validation = test_validation_split["train"]
dataset_test = test_validation_split["test"]compute_dtype = getattr(torch, "float16")
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type='nf4',
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=False,
)model_name='microsoft/phi-2'
device_map = {"": 0}
original_model = AutoModelForCausalLM.from_pretrained(model_name,
device_map=device_map,
quantization_config=bnb_config,
trust_remote_code=True,
use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained(model_name,trust_remote_code=True,padding_side="left",add_eos_token=True,add_bos_token=True)
tokenizer.pad_token = tokenizer.eos_tokenmodel = prepare_model_for_kbit_training(model)
config = LoraConfig(
r=32,
lora_alpha=32,
target_modules=[
'q_proj',
'k_proj',
'v_proj',
'dense'
],
bias="none",
lora_dropout=0.05,
task_type="CAUSAL_LM",
)
model.gradient_checkpointing_enable()
peft_model = get_peft_model(model, config)peft_training_args = TrainingArguments(
output_dir = output_dir,
warmup_steps=1,
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
max_steps=1000,
learning_rate=2e-4,
optim="paged_adamw_8bit",
logging_steps=25,
logging_dir="./logs",
save_strategy="steps",
save_steps=25,
evaluation_strategy="steps",
eval_steps=25,
do_eval=True,
gradient_checkpointing=True,
report_to="none",
overwrite_output_dir = 'True',
group_by_length=True,
)
peft_model.config.use_cache = False
peft_trainer = transformers.Trainer(
model=peft_model,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
args=peft_training_args,
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False),
)def generate_response(prompt, max_length=100):
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
with torch.no_grad():
output = peft_model.generate(**inputs, max_length=max_length)
response = tokenizer.decode(output[0], skip_special_tokens=True)
return response
prompt = "What to do when feeling unmotivated?"
response = generate_response(prompt)
print("Generated Response:", response)