Overview
In this blog I attempt to explain FSDP, highlighting its significance in optimizing memory usage and scaling training across multiple GPUs.
I then explain how FSDP works, detailing the process of parameter sharding, gradient synchronization, and checkpointing. A dedicated section compares FSDP1 vs FSDP2, outlining the limitations of the original implementation and the improvements introduced in FSDP2.
Finally, I demonstrate how to implement FSDP2 using PyTorch, providing practical guidance for integrating it with LoRA during fine-tuning.
Introduction
Training AI models at a large scale is a challenging task that requires a lot of compute power and resources. It also comes with considerable engineering complexity to handle the training of these very large models.
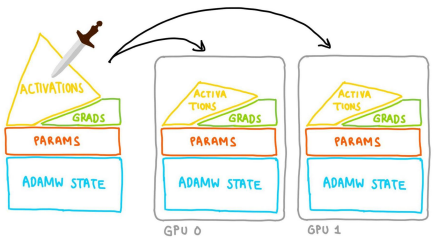
Fully Sharded Data Parallel (FSDP) makes it easier for us to efficiently train very large neural network models that would otherwise exceed the memory capacity of a single GPU. FSDP achieves this by sharding (splitting) model parameters, optimizer states, and gradients across multiple GPUs, rather than replicating the entire model on each device as in traditional data parallelism.
This approach hence brings us the following benefits:
- Enabling Training of Larger Models
- Improves Memory Efficency
- Optimizes Computational Resources
- Flexible and Scalable
- Reduces Redundancy (Don't need full model copies on each device)
How FSDP works ?
When training with FSDP, the GPU memory footprint is smaller than when training with DDP across all workers. This makes the training of some very large models feasible by allowing larger models or batch sizes to fit on device. This comes with the cost of increased communication volume. The communication overhead is reduced by internal optimizations like overlapping communication and computation.
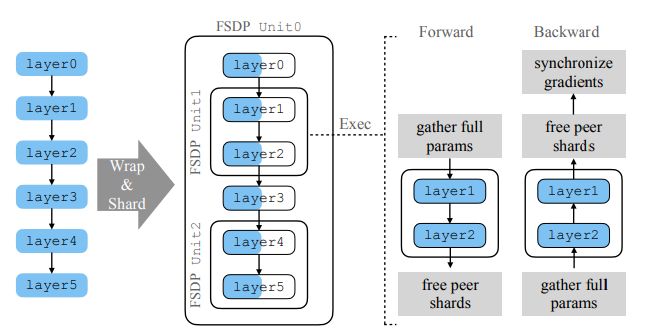
At a high level FSDP works as follows:
In constructor
- Shard model parameters and each rank only keeps its own shard
In forward path
- Run all_gather to collect all shards from all ranks to recover the full parameter in this FSDP unit
- Run forward computation
- Discard parameter shards it has just collected
In backward path
- Run all_gather to collect all shards from all ranks to recover the full parameter in this FSDP unit
- Run backward computation
- Run reduce_scatter to sync gradients
- Discard parameters
An implmentation of FSDP can be found here: How to use FSDP
FSDP1 Vs FSDP2
First, we want to understand how FSDP1 and FSDP2 work internally to understand the differences between them. This also helps us understand the limitations of FSDP1 and how FSDP2 solves them.
Lets visualize this and understand what the problem is....
Lst's say we have a single layer that contains 3 linear layers and is wrapped using FSDP1 to be sharded accross 2 GPUs
FSDP1
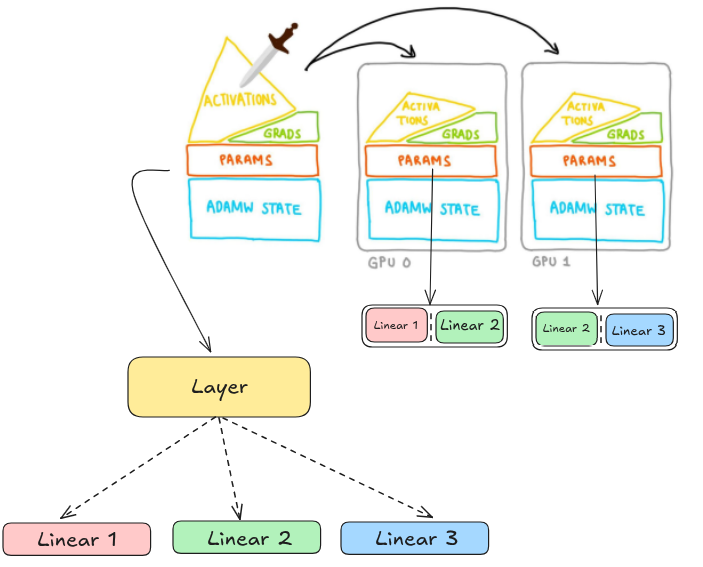
The whole Layer gets flattened into a single FlatParameter, which then gets sharded across ranks. However, this FlatParameter complicates applying different behaviors to individual parameters within the FlatParameter, e.g. parameter freezing, parameter casting, etc., hurting composability, and it complicates the internal implementation, e.g. making state dict logic thousands of lines and requiring additional communications.
FSDP2
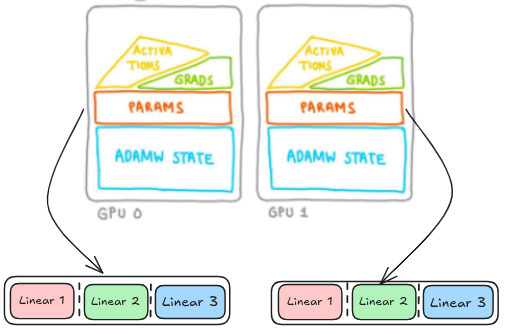
FSDP2 represents sharded parameters as DTensors sharded on dim-0, allowing for easy manipulation of individual parameters, communication-free sharded state dicts, and a simpler meta-device initialization flow.
FSDP2 implements an improved memory management system that achieves lower and deterministic GPU memory by avoiding recordStream and does so without any CPU synchronization.
Implementing LoRA+FSDP2
The following steps outline the implementation of FSDP2 with LoRA for fine-tuning a large language model (LLM). For details on LoRA, please refer to my earlier blog here.
Setting up Model and LoRA configurations
model = AutoModelForCausalLM.from_pretrained(
base_model,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
use_cache=False,
)
model.gradient_checkpointing_enable()
# ---- LoRA Configuration ----
lora_config = LoraConfig(
r=8,
lora_alpha=16,
target_modules=["q_proj", "v_proj", "k_proj", "o_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
model = get_peft_model(model, lora_config)
model = model.to(torch.bfloat16)
for param in model.parameters():
param.requires_grad = False
for name, param in model.named_parameters():
if "lora" in name.lower():
param.requires_grad = TrueTo optimize memory usage, we load the model using the bfloat16 data type instead of the default float32. This significantly reduces memory consumption while maintaining numerical stability, especially on hardware that supports bfloat16 natively. For a deeper understanding of the differences between float32, float16, and bfloat16, you can refer to this article. Additionally, gradient checkpointing is enabled after loading the model to further optimize memory efficiency. This technique reduces memory usage during backpropagation by storing only a subset of activations and recomputing the rest on the fly.
To enable parameter-efficient fine-tuning, we configure and apply LoRA (Low-Rank Adaptation) to the model. LoRA allows us to inject trainable low-rank matrices into specific layers (such as "q_proj", "k_proj", "v_proj", and "o_proj") of the transformer architecture. We use a rank of 8 and an alpha value of 16 for scaling. After applying LoRA using the get_peft_model() function, we convert the model to bfloat16 precision for efficient memory usage. We then freeze all base model parameters and selectively unfreeze only the LoRA layers. This setup ensures that only a small subset of parameters is updated during training, drastically reducing memory and compute requirements without compromising performance.
world_size = dist.get_world_size()
device_mesh = init_device_mesh("cuda", (world_size,))
fsdp_kwargs = {
"mp_policy": MixedPrecisionPolicy(
param_dtype=torch.bfloat16,
reduce_dtype=torch.bfloat16,
),
"offload_policy": OffloadPolicy()
}
from transformers.models.llama.modeling_llama import LlamaDecoderLayer
for module in model.modules():
if isinstance(module, LlamaDecoderLayer):
fully_shard(module, mesh=device_mesh, **fsdp_kwargs)
fully_shard(model, mesh=device_mesh, **fsdp_kwargs)To enable memory-efficient distributed training, we apply Fully Sharded Data Parallel (FSDP2) using PyTorch’s native APIs. We begin by initializing a device mesh across all available GPUs, which defines how model parameters are partitioned across devices. A MixedPrecisionPolicy is then configured to use bfloat16 for both parameter storage and inter-device communication, enabling faster computation and lower memory consumption. We also include an OffloadPolicy to optionally move parameters or optimizer states to the CPU when necessary. Since FSDP2 requires all model parameters to be in the same data type, we explicitly convert the model to bfloat16 before wrapping it. The sharding is first applied selectively to each LlamaDecoderLayer, providing fine-grained control, and then the entire model is wrapped with fully_shard() to finalize the setup. This allows efficient fine-tuning of large models across multiple GPUs with significantly reduced memory overhead.
Complete code for LoRA+FSDP2 can be found here.
Summary
When fine-tuning large language models like LLaMA-3.1-8B, GPU memory becomes a major bottleneck. This is where FSDP2 (Fully Sharded Data Parallel v2) comes into play. FSDP2 shards the model’s parameters and optimizer states across multiple GPUs, dramatically reducing per-GPU memory usage while enabling training at scale. In our setup, we use LoRA (Low-Rank Adaptation) to fine-tune the model in a parameter-efficient manner — updating only a small fraction of weights (e.g., ~50MB). By freezing the base model and training only the LoRA layers, we drastically cut down the size of gradients and optimizer states.
Lets say for example we have a 4 GPU cluster, then a 16GB model in bfloat16 would be split across the GPUs with each GPU holding only 4GB of parameters. Even after accounting for communication and gradient synchronization overhead, total memory per GPU stays in the ~6–8GB range — far below what would be required for full fine-tuning without FSDP (which could exceed 90GB per GPU).
In summary, FSDP2 + LoRA allows:
- Fine-tuning of large models with reduced memory overhead
- Training only LoRA layers while sharding the rest
- Feasibility of training large models even on modest GPU setups