
Introduction
Models come in two types : pretrained, and fine-tunes. Many applications in natural language processing rely on adapting one large-scale, pre-trained language model to multiple downstream applications. Such adaptation is usually done via fine-tuning, which updates all the parameters of the pre-trained model. The major downside of fine-tuning is that the new model contains as many parameters as in the original model. As larger models are trained every few months, this changes from a mere inconvenience to a critical deployment challenge.
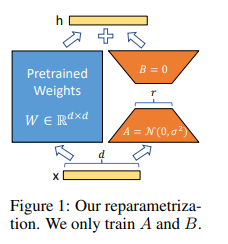
A LoRA is a sort of finetune that is very very specific. It's so efficient it can be done in half an hour on a consumer grade gaming computer. It works by inserting a smaller number of new weights into the model and only these are trained. This makes training with LoRA much faster, memory-efficient, and produces smaller model weights (a few hundred MBs), which are easier to store and share.
Implementation
- Loading dataset:
I am using the dataset from alfredplpl/anime-with-caption-cc0 but since it is very big I have scrapped 2000 images from this and saved them in this dataset sharmaarush/text_to_anime
from datasets import load_dataset
dataset = load_dataset("sharmaarush/text_to_anime")!git clone https://github.com/huggingface/diffusers
!pip install /content/diffusers
!pip install -r /content/diffusers/examples/text_to_image/requirements.txt
!wget https://raw.githubusercontent.com/huggingface/diffusers/main/examples/text_to_image/train_text_to_image_lora.py
# Initialize an 🤗 Accelerate environment:
from accelerate.utils import write_basic_config
write_basic_config()import os
os.environ["MODEL_NAME"] = "runwayml/stable-diffusion-v1-5"
os.environ["OUTPUT_DIR"] = "/content/drive/MyDrive/finetune_lora/anime"
os.environ["DATASET_NAME"] = "sharmaarush/text_to_anime"
os.environ["HUB_MODEL_ID"] = "anime-lora"!accelerate launch --mixed_precision="bf16" train_text_to_image_lora.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_NAME \
--dataloader_num_workers=2 \
--resolution=512 \
--center_crop \
--random_flip \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--max_train_steps=500 \
--learning_rate=1e-04 \
--max_grad_norm=1 \
--lr_scheduler="cosine" \
--lr_warmup_steps=0 \
--output_dir=$OUTPUT_DIR \
--checkpointing_steps=250 \
--caption_column="prompt" \
--validation_prompt="1girl, school uniform, flower garden background" \
--seed=1337 \
--allow_tf32from huggingface_hub import create_repo, upload_folder
repo_name = "anime_lora"
create_repo(repo_name, private=False)
upload_folder(
folder_path="/content/drive/MyDrive/finetune_lora/anime",
repo_id=f"{'sharmaarush'}/{repo_name}",
commit_message="Initial upload of fine-tuned text-to-image LoRA model"
)# First load the base model
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16).to("cuda")
# Then load your lora weights
pipeline.load_lora_weights("sharmaarush/anime_lora", weight_name="pytorch_lora_weights.safetensors")image = pipeline("1girl, :3, animal ear fluff, animal ears, apple, arms up, black skirt, black thighhighs, blue shirt, blush, braid, brown eyes, brown hair, collared shirt, cookie, food, fruit, garter straps, hand up, long hair, long sleeves, looking at viewer, looking to the side, multicolored hair, open mouth, pink background, school uniform, shirt, simple background, skirt, smile, streaked hair, thighhighs, very long hair, zettai ryouiki").images[0]
image